YT: stork
YouTube
jameslittle230/stork
https://github.com/jameslittle230/stork
why?
毎週送られてくるStackShareの Weekly メールで存在を知り、静的サイトに検索つけられると便利そうだなーと思ったのがきっかけ。最近 WebAssembly が気になっているというのもあり。 ブログとかドキュメントサイトとかを GitHub Pages でホストすることがあるけど、Algoriaとか設置するのはちょっと重めな気がするので、WebAssembly で実現できると取り回し良さそうだなと思い、使い勝手を試してみた。
what?
Static Site / JAM Stack なサイトに検索機能を追加する WebAssembly 製のツール。Rust 製。
事前にインデックスファイル(.st)を生成しておき、そのインデックスファイルの内容を検索する機能を持つ WebAssembly ファイル(.wasm)と JavaScript(.js)をサイトに追加することでサイト上に検索機能を付けることができる。WebAssembly ファイルと JavaScript ファイルは基本的に公式で配布されているものを使うので、実質インデックスファイルを用意するだけ。
インデックスファイル(.st)は、ローカルにあるファイルをstorkコマンドで parse して生成する。storkコマンドも Rust で書かれてるっぽい。
公式ドキュメントを見ると、日本語含む CJK 言語の対応は難しいのかなと見えたけど、実際にインデックスファイルを作成してみると日本語の検索も普通にできそう。
Roadmapを見ると個人プロジェクトとして開発されているらしい。開発者は Stripe の人。
How?
公式ドキュメントに Quick Start Guide があるので、まずはそれに沿って動かしてみた。Federalist Paperというエッセイ?のインデックスファイルがデモ用に配信されており、それを使った検索機能のお試しページを作ってみようというもの。
Demo
以下のindex.htmlを作成し、ブラウザで開けばそれだけで使える。簡単。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Federalist Search</title>
<link rel="stylesheet" href="https://files.stork-search.net/basic.css" />
</head>
<body>
<div class="stork-wrapper">
<input data-stork="federalist" class="stork-input" />
<div data-stork="federalist-output" class="stork-output"></div>
</div>
<script src="https://files.stork-search.net/stork.js"></script>
<script>
stork.register(
"federalist",
"https://files.stork-search.net/federalist.st"
);
</script>
</body>
</html>
stork.jsを読み込むだけで内部で WebAssembly ファイルもダウンロードされるため、機能的に読み込む必要があるのはこのファイルだけ。デザイン用にbasic.cssとdark.cssが用意されているため、それも使う。CSS については、今後拡充予定らしい。
stork.jsを読み込むと、stork.register()関数が使えるようになるので、ここで事前に作成しておいたインデックスファイル(.st)を読み込ませる。第 1 引数に任意の名前を指定し、第二引数にインデックスファイルの場所を指定する。デモ用にFederalist Paperの内容をインデックスファイル化したものがhttps://files.stork-search.net/federalist.stから取得できるため、これを第 2 引数に指定する。第 3 引数には各種オプションが指定できる。
https://stork-search.net/docs/js-ref
stork.register()関数で読み込ませたデータの検索機能を画面上に表示するには、以下のような HTML を書く。
<div class="stork-wrapper">
<input data-stork="federalist" class="stork-input" />
<div data-stork="federalist-output" class="stork-output"></div>
</div>
ここで、data-stork属性の値として設定する文字列は、stork.register()関数の第一引数に指定した任意の名前に準じる。input要素のdata-stork属性には第一引数の値をそのまま、検索結果を表示する要素(divじゃないとダメ?)の方のdata-stork属性には、第一引数の文字列の後ろに-outputを付けた文字列を指定する。
実際の検索処理は以下のように動作する。
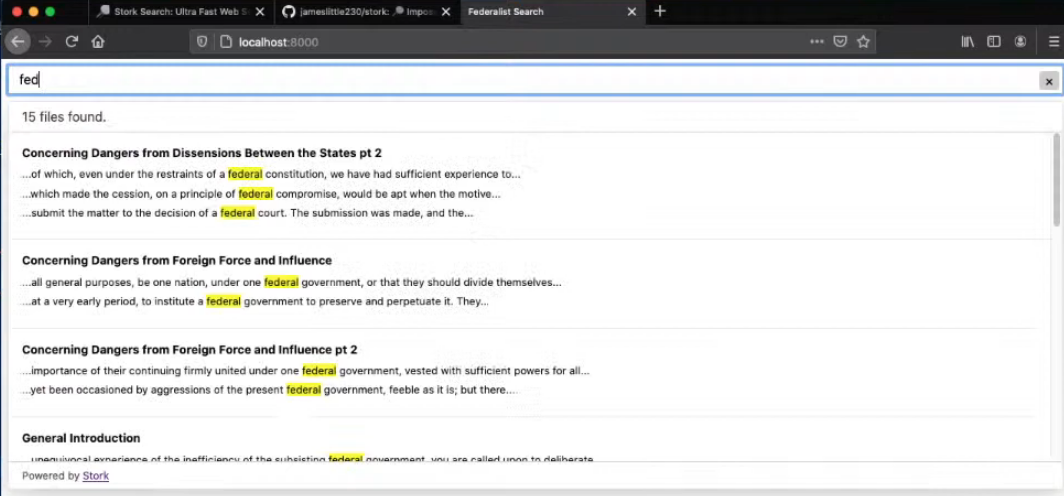 https://youtu.be/qkiHTEG1yds?t=698
https://youtu.be/qkiHTEG1yds?t=698
簡単便利。
Create index file
次に、独自のインデックスファイルを作る。
インデックスファイルは storkコマンドを使って生成するため、まずはstorkコマンド実行環境を作る必要がある。インストール方法は公式ドキュメントを参考。
https://stork-search.net/docs/install
自分は macOS で作業しているけど、HomeBrew でインストールしようとしたところcargo installに非常に時間がかかりインストールが終わらなかったので、GitHub のリリースページからバイナリを入手した。
storkコマンドでインデックスファイルをつくるには、どのファイルを元にインデックスファイルを作のかを記述した設定ファイルを TOML 形式で作成しておく必要がある。設定ファイルの公式リファレンスは下記。
今回は、自分のブログページのインデックスファイルを作ることにした。
[input]
base_directory = "../orta-contrib.github.io/content/posts/youtube"
url_prefix = "https://orta-contrib.github.io/posts/youtube"
files = [
{path = "20201015-vscode-debug-visualizer.md", url = "/20201015-vscode-debug-visualizer", title = "20201015-vscode-debug-visualizer"},
{path = "20201016-vscode-foam.md", url = "/20201016-vscode-foam", title = "20201016-vscode-foam"},
{path = "20201023-actionsflow.md", url = "/20201023-actionsflow", title = "20201023-actionsflow"},
{path = "20201028-bubbletea.md", url = "/20201028-bubbletea", title = "20201028-bubbletea"},
{path = "20201106-ffmpeg-wasm.md", url = "/20201106-ffmpeg-wasm", title = "20201106-ffmpeg-wasm"}
]
[output]
filename = "my_index.st"
input.files にインデックス化対象のファイルを羅列する。 pathにinput.base_pathからの相対パスを、url に 検索結果をクリックした時の遷移先 URL を、title に検索結果に表示されるタイトルを指定する。 インデックスファイルの出力先はoutput.filenameに指定する。
設定ファイルを作成したら、 stork コマンドを実行する。
まずは、テスト用のサイトを立ち上げてくれるtest用のコマンドを実行。
$ ./stork —test config.toml
コマンドが成功するとhttp://localhost:1612でテスト用のサイトが立ち上がるのでアクセスすると、検索窓があるのでそこでインデックスファイルの動作を確認できる。
日本語は非対応かと思っていて、どの程度使えそうかを試すために自分のブログを対象にしてみたけど、なんだか普通に検索できてそうな感じ。
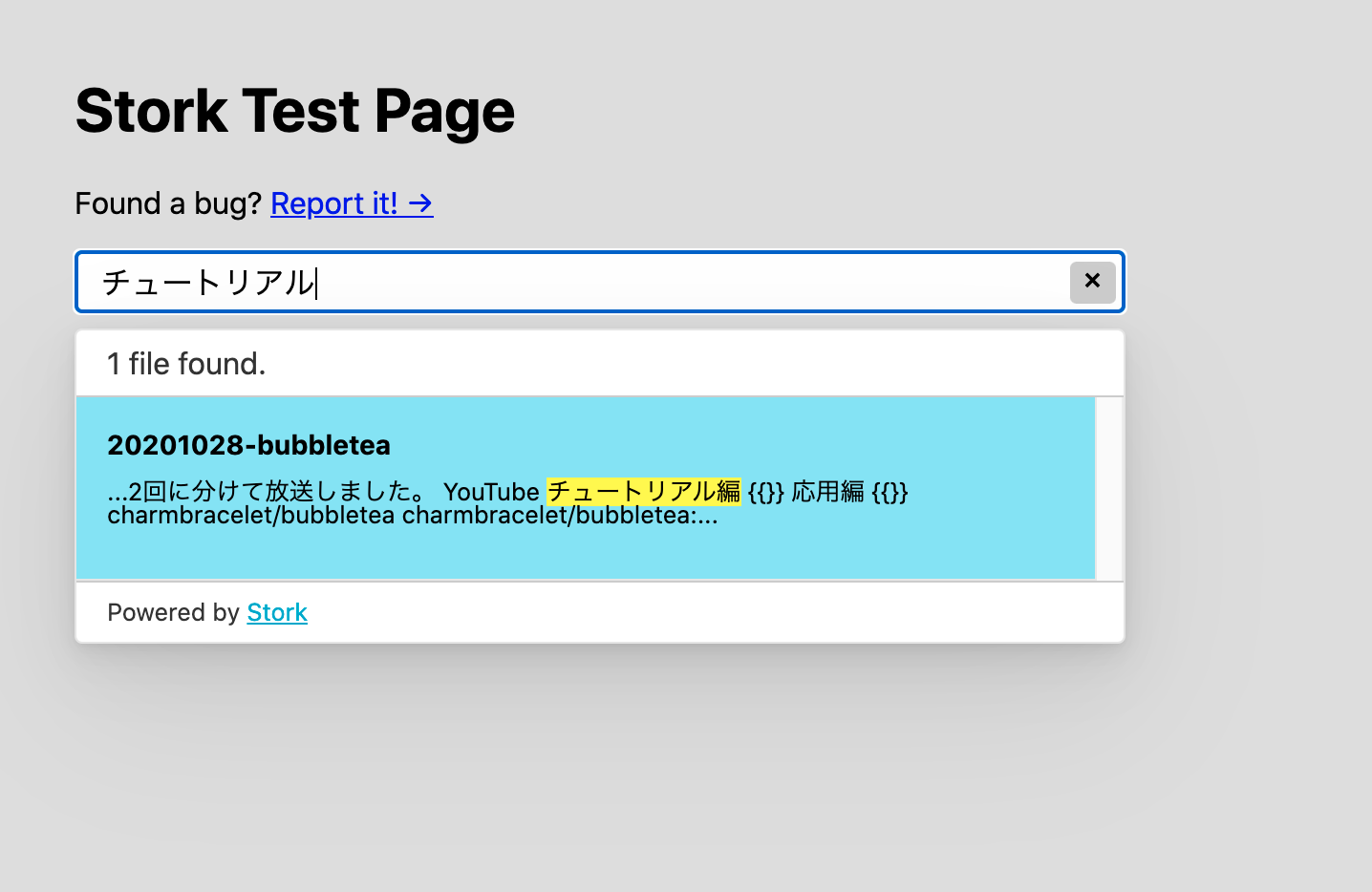
動作に問題なさそうならインデックスファイルを作成する。
$ ./stork —build config.toml
コマンドが成功すると config.toml の output.filename で指定したパスにインデックスファイルが生成されるので、前述の HTML ファイルの .st ファイルの部分を、このファイルのパスに置き換えることで、自作のインデックスファイルを有効にできる。
—–
最終的に出来上がった自分のブログの検索サイトが下記のページ。(検索窓しかない… )
GitHub Actions とかでブログ更新するたびにインデックスファイル作成して更新とかする仕組みを作れば良い感じに運用できそうな気がする。その場合インデックスファイルはどこに置くのがいいんだろうな。リポジトリに入れるのは更新のたびにインデックスファイルの push が走るのでコミット履歴が冗長になるし、Release ページに置くにしても毎コミット新しいリリース作るのは億劫な。CDN とかに置くのがいいのかな。公式ドキュメントでも Netlify で CDN でみたいな利用方法が書いてあった気がする。
Impression
設定数行書くだけで検索機能を設置できるのでとても便利そう。インクリメンタルに検索してくれるし、日本語も対応してるみたいだし。 インデックスファイル作成も自然な感じで実行できるので CI で回したりするのも楽そう。自分のブログに設置して、GitHub Actions でインデックスファイル作成するプロセス回してみようかな。
Contribute
特になし(質の高い個人プロジェクトでした…)